In the last quarter of 2016 the German marketing team came up with a great way to follow the immense success of last year’s Tableau Stadium Tour: the Tableau Cinema Tour! After visiting ten cities all over Germany, Austria, and Switzerland, we are now considering rolling it out all over Europe. Stay tuned for that! Since we often got requests for the data used in the main demo, I decided to produce this write-up of how to extract the data from the Internet Movie Database (IMDb). Unfortunately copyright reasons make it impossible for us to just provide you the ready-made data. That said, with this walk-through everybody should be able to get the data!

Tableau Cinema Tour
The Tools
- The collection of data and main extraction of the usable information is happening using a number of Python scripts. For the following to work we assume Python 2.7 on your machine – I haven’t tested the scripts on Python 3.
- You’ll need a tool that allows to extract
.gzfiles. On Linux machines I’d recommendgziporgunzip, for Windows 7zip is a good free option – commercial WinZip can also handle them. - The main script writes the output data directly into a PostgreSQL database So you will need access to that. The default setup of the scripts assumes a local installation, but a remote database will also work. I developed and tested the scripts using PostgreSQL 9.5.
- You’ll also need a text editor. Personally I like Notepad++, but any given editor should be fine. Alternatively you could resort to a true Python IDE such as Spyder. For having a look into the rather massive source data files I also recommend Sublime.
- It probably won’t be necessary for simply using the scripts, but since they make heavy use of regular expressions I used regex101.com a lot. (Hint: Don’t forget to set the “flavor” on the left to “Python”…)
- And of course we need Tableau, to visualize the data!
The Source Data
The data for the Tableau Cinema Tour stem from what is most likely the most famous and complete source for anything and everything about movies, cinema, and TV: the Internet Movie Database (IMDb). According to their own statistics the IMDb currently contains data on 4,431,127 productions and 8,047,620 people. Of course one could just start to crawl and download all that data, but this would not only be against their terms of usage but would also probably be awfully slow. Since the IMDb changes so quickly inconsistent data would probably the outcome.
IMDb
Therefore it’s a lot easier to just download the complete IMDb in one go! Unfortunately the data model underlying the IMDb is not just available for download. That would be too easy and also defy the existence of this blog post. Well hidden under the headline “Alternative Interfaces” it is possible to download “Plain Text Data Files”. Since I’m in Germany I used the mirror at the FU Berlin – thanks to all the people providing IMDb mirror sites!
If you (just as myself) think there should be an IMDb API, please feel free to participate in this survey!
The Workflow
Introduction
The following might be a bit technical. That said, it’s not necessary to understand every single step in detail to be able to use the script and get the data. If you encounter any issues, feel free to ask in the comments.
I didn’t start from scratch but built upon the great work done by Ameer Ayoub which is available on his GitHub repository for download. The script reads the source files, parses them into a more usable format, and then saves the results into a database. Sounds straight enough, but isn’t as it turned out. Which can also be guessed by the sheer length of the source code! Yet, Ameer did a great job in making his script very modular and well commented, while at the same time keeping it flexible and extensible. So I forked and extended his repository. While Ameer had mostly the reusability in mind when writing his code, I aimed it explicitly at the planned usage for the Tableau Cinema Tour. So while I extended the code with topics like ratings, business data, filming locations, and biographical data I did all this exclusively for PostgreSQL as a backend. So if anyone is planning to use it with MySQL or SQLite in the background please feel free to extend my code accordingly. PostgreSQL works out-of-the-box.
Step 0: Preparations
All the tools mentioned above should be installed and tested. The Python install can be tested by entering python on a command line. The result should look like this:

Python test on Windows
The easiest way out of the Python command line interface (indicated by the >>>) is by entering exit(). All the examples shown in this blog post were run on a Windows machine, but the code is platform independent so it should work on OS X macOS and Linux.
Step 1: Download the Script
Ameer’s script with my changes and extensions is available on my GitHub repository and can be either forked, cloned, or downloaded as a ZIP archive.

GitHub: clone or download repository
Step 2: Download the Source Data
The IMDb data themselves can be easily downloaded from the above-mentioned FTP server at FU Berlin:
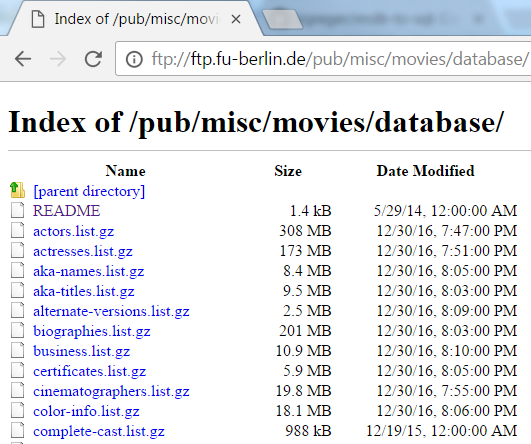
IMDb files on the FTP server at FU Berlin
They are zipped text files with the extension .list. The script in its current version uses only the following files:
actors.list.gzactresses.list.gzbiographies.list.gzbusiness.list.gzlocations.list.gzmovies.list.gzratings.list.gz
To make the execution of the script as painless as possible (read: without having to make too many changes) I recommend to save those files into a sub folder of the scripts’ location. Ideally it should be called imdb-list. (Hint for GitHub users: exclude this sub folder in your .gitignore – otherwise all the data will be synced into your repository…) The .gz files can be deleted after unpacking them:
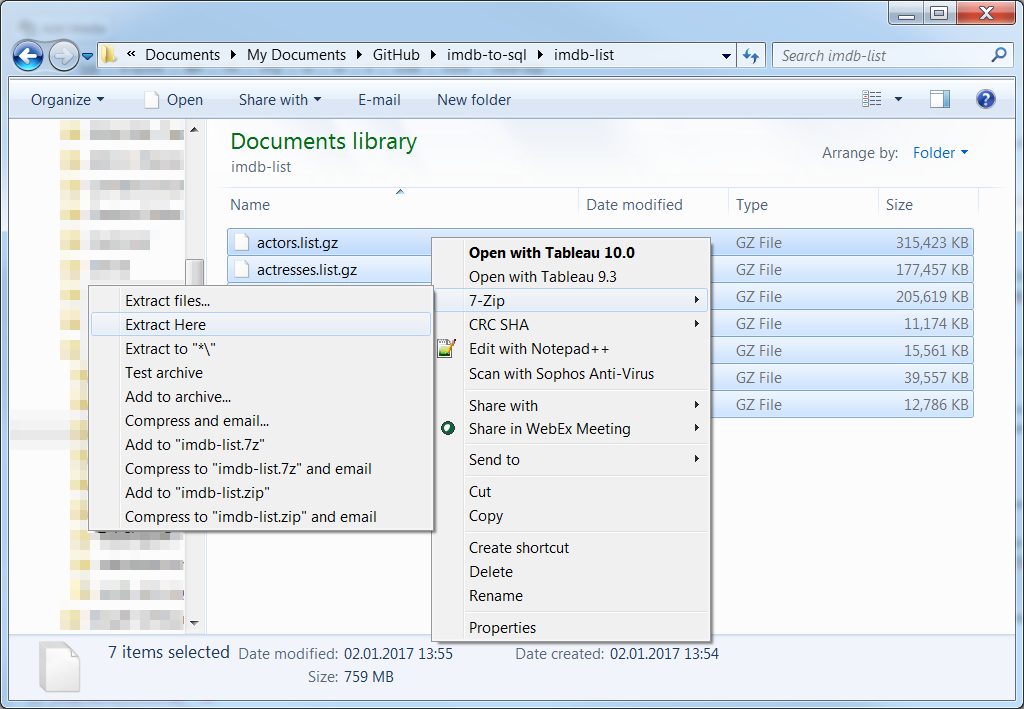
Extract .gz files with 7zip
Also, the text files’ encoding needs to be changed to UTF-8 from ISO-8859-1 (“Latin-1”). This can be done very easily in a text editor. In Sublime using File > Save with Encoding > UTF-8; in Notepad++ using Encoding > Convert to UTF-8 and then File > Save.

Saving with different encoding in Sublime
Step 3: Tailoring the Script
This is probably the hardest bit. But you should be alright if you followed my recommendations earlier and want to keep everything on the default settings. There might be cases where the script needs to be run multiple times before everything works as expected, but nothing can go catastrophically wrong, so don’t fret.
What I so far referred to as “the script” is actually a collection of multiple Python source files (indicated by the .py file extension) and SQL code (indicated by the extension .sql in sub folder schemas). Both the code and the SQL queries are commented sufficiently to understand quickly what’s going on. This shouldn’t even be necessary for most readers, unless you really want to understand how they work.
The most central component is the tosql.py file. It takes care of both parsing of the input files using regular expressions and saving the output data into the database. The file settings.py contains, as you might suspect from the file name, all the main settings to the script. Furthermore the script needs to call the files postgres.drop.sql and postgres.use_dict.sql from sub folder schemas to initialize the database. The files postgres.index.sql and postgres.postprocess.sql will be run manually in the end.
A good starting point is to take care of the basic settings in settings.py. By default it looks like this:
class DatabaseTypes: SQLITE = 0 MYSQL = 1 POSTGRES = 2 # script configuration # database options class Database: type = DatabaseTypes.POSTGRES# database type, one of DatabaseTypes database = "imdb_data" # database name encoding = "utf-8" # used to pre-encode the queries to drop any invalid characters # for the database type host = "127.0.0.1" # database host user = "postgres" # database username password = "postgres" # database password clear_old_db = True # clear old database information if exists # general options class Options: list_dir = ".\imdb-list" # directory of the imdb list files file_extension = ".list" # file extension for the imdb list files query_debug = False # show log of all sql queries at construction time show_progress = True # show progress (at all) progress_count = 10000 # show progress every _n_ lines commit_count = 10000 # commit every _n_ lines, -1 means only on completion # database will commit on completion of each file regardless show_time = True # show the total time taken to complete use_native = False # use native parsing operations instead of regex use_dict = True # use a dictionary to generate and cache db id's in program use_cache = False # cache the dictionaries to the disk, must be enabled if you # you want to convert only some files and you want to use dict schema_dir = "schemas" # directory to load the db schemas from cache_dir = "cache" # directory to load the dictionary caches from if applicable proc_all = True # overrides the individual process directives
The parts needing our attention are marked above:
- Line 10 holds the name of the database we create in PostgreSQL – by default that’s
imdb_data. - Line 13 holds the database server’s address – by default that’s
127.0.0.1for a local server. - Lines 14 and 15 hold the login credentials for the database.
- Line 16 defines whether an existing database should be wiped when the script starts. That’s probably a good idea unless you’re doing some testing with parts of the script. Hence the default here is
True. - Line 20 holds the path where the script will look for the input files – by default that’s the
imdb-listsub folder as mentioned above.
It might also be interesting to set the flag query_debug to True if you’re interested in a very detailed output of what the script is doing at each given time. Note that this has very heavy implications on the performance, therefore this setting should only be active during testing. The options progress_count and commit_count define how often the script should print status information or write the data from memory to the database, respectively. With the latter a setting of -1 means that the data will only be persisted to disk in the very end of each file. This obviously increases the memory footprint, hence I advise against it – unless you have a good reason to do so. Lastly, the parameter proc_all can assure that all input files will be processed. In case it’s set to False lines 497-504 in the main script tosql.py will define which files will be processed. This is also only for testing purposes:
process_flags = {
"people": False,
"productions": False,
"ratings": True,
"business": True,
"locations": True,
"biographies": True
}
Step 4: Prepare the Database
The PostgreSQL database our outout data will be written to needs to be created before running the script. The easiest way to do that is a graphical user interface such as pgAdmin, which is either installed together with PostgreSQL or can be downloaded and installed manually from website. Of course it can also be done on the command line. Here I opted for imdb_data as the database name, which means I won’t have to change it in the settings script (see above). Another important aspect is the fact that the owner of this new database is the user referenced in line 14 of file settings.py – in my case postgres.
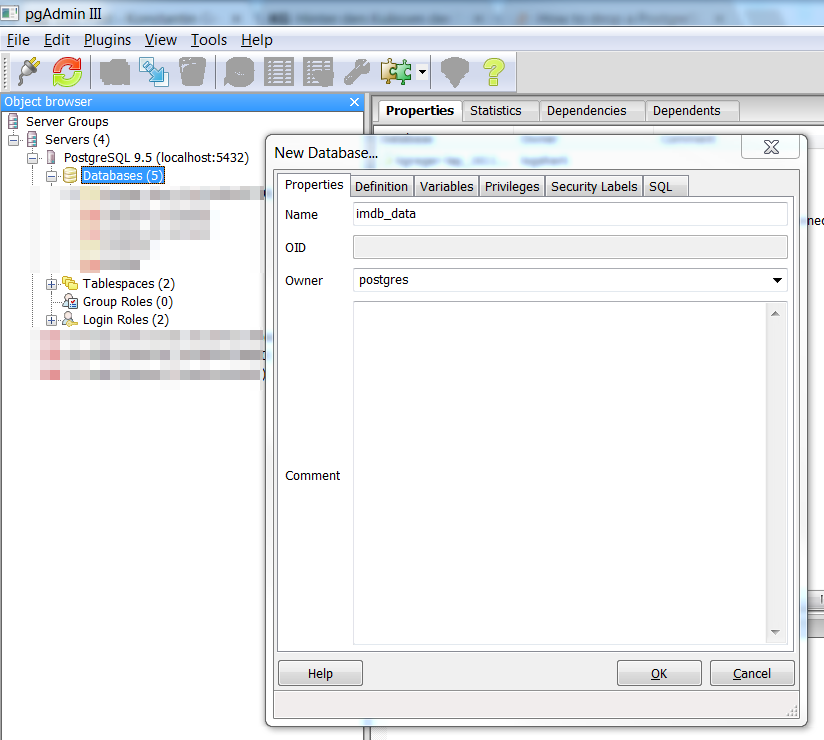
Creating a new database in pgAdmin III
The resulting SQL statement:
CREATE DATABASE imdb_data
WITH ENCODING='UTF8'
OWNER=postgres
CONNECTION LIMIT=-1;
Step 5: Run the Script
When all preparations are done we can release the Kraken run the script! The main script is started by entering python tosql.py on the command line. Of course we need to be in the correct folder, otherwise the path needs to be given as well.
The code itself is neither very efficient nor highly performant, therefore the execution takes quite a while – about 5.5 hours on my mid-class laptop machine. But we all know the old software development adage: If code optimization takes longer than the time saved by it it’s not really worth it. Ideally this script will only run once, so…
During run time a few messages will appear on your screen:

Warnings in script tosql.py
You can easily ignore these. The script just came across a few data sets the regular expressions couldn’t handle properly – mostly because of inconsistent use of quotation marks in the text files. These data sets will be missing in the output data, but due to their very small number I decided against looking into the regex issue any deeper. Maybe you would like to fix it…?
The script ends with a print out of the total run time in seconds:
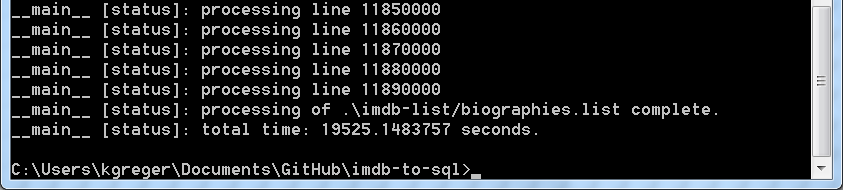
Summary at the end of script tosql.py
Step 6: Create Indices and Post-process Data
Indices help us with the performance of the IMDb data, which are waiting for us in the PostgreSQL database after the main script is done. We use the script index.py by entering python index.py on the command line to create the indices:

Running index.py on the Windows command line
I didn’t create another Python script for the remaining changes, so we need to do those directly inside the PostgreSQL database. Ideally using a graphical user interface like pgAdmin. The steps are contained in the file postgres.postprocess.sql in the schemas sub folder. It can be executed in one go:
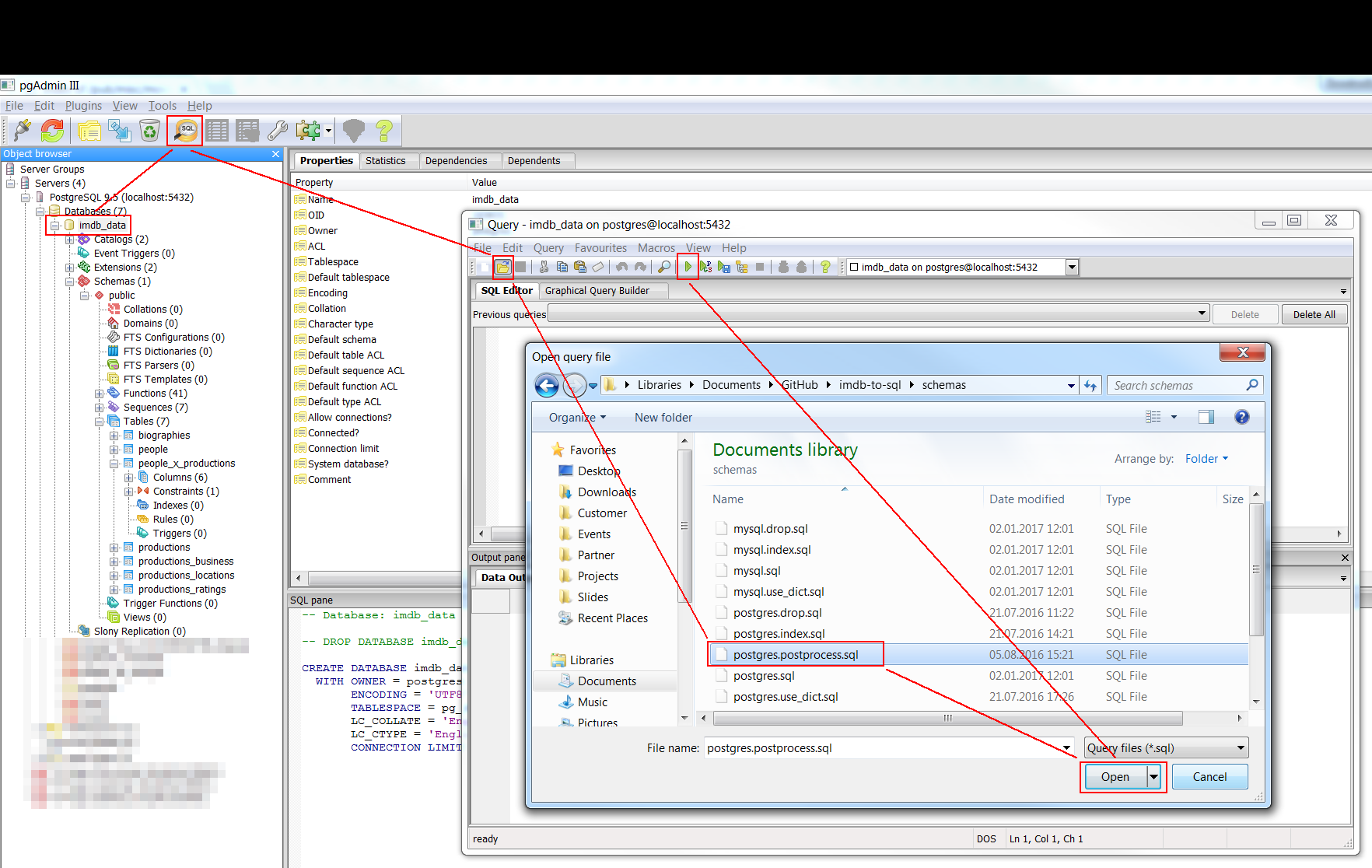
Running a query from a .sql file in pgAdmin III
After connection to the correct database (here imdb_data) we just need to click the Query button, select the Open button and the correct file (here postgres.postprocess.sql) and finally click on the Run button with the green play symbol.
Command line freaks can issue the command using psql -U postgres -d imdb_data -a -f postgres.postprocess.sql – in order for this to work you should have the path to your PostgreSQL binaries (C:\Program Files\PostgreSQL\VERSION\bin) in your PATH variable. The sections in italics might need to be set accordingly.
If you’re planning to work with the IMDb raw data you should stop here and get started with your analyses! If you want to have the exact dataset we used at the Tableau Cinema Tour please run script postgres.postprocess.sql.
Step 7: Done!
Congratulations, you now have the complete IMDb (well, the parts we downloaded…) in your PostgreSQL database, all indexed and nicely prepared for you to analyze away! Even though I recommend against it for performance reasons, this is how you can rebuild the complete data model in Tableau:

Complete data model for imdb_data in Tableau
For the purposes at the Tableau Cinema Tour we didn’t even look into most of these data since it was mostly about the productions. The script postgres.postprocess.sql joined the data from table biographies to the people data in table people. It also joined the production cost and box office results from table business to the productions in table productions. I also added a few filters to iron out some very obvious data errors: people aged less than 0 or more than 120 years during production; as well as productions that cost less than 0 or more than 350 million US dollars, or had box office returns of less than 0 or more than 2.8 billion US dollars in total or more than 250 million US dollars on opening weekend were removed. These values might have to be corrected at some point, but currently they match the real situation. I also decided to remove all productions that are neither a feature film nor a TV series, like e.g. computer games, DVDs and things like that.
Some of the field names in the database might still be a bit too cryptic for some people. For them I created a Tableau Data SourceTableau Kino Tour.tds (right-click > Save target as...). It uses exclusively the table productions – that’s all we used for the main demo of the Tableau Cinema Tour. When loading up the .tds file Tableau is going to ask for the PostgreSQL credentials (here postgres/postgres). In case the PostgreSQL database is running on a remote system the connection parameters also need to be changed using Edit connection.
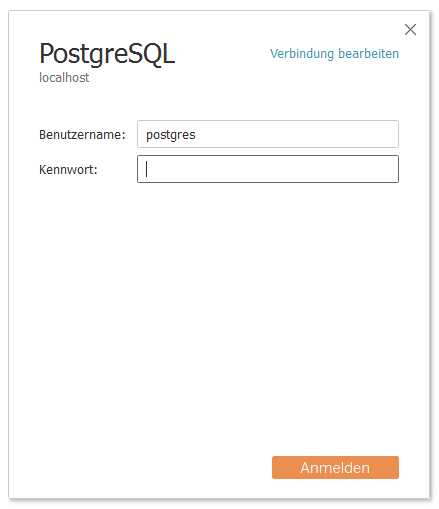
Connect to the imdb_data database
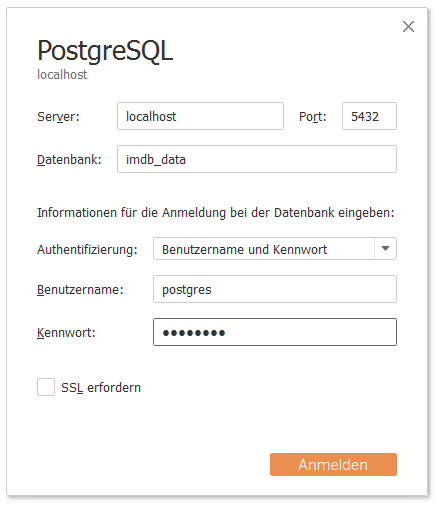
Edit connection parameters for imdb_data database
In order to get the highest possible performance out of our IMDb data we finally create a Tableau Extract (.tde file). The easiest way is to right-click on the data source “Tableau Kino Tour” on the top-left > Extract... and then click the button “Extract” in the newly opened dialog window.

Extracting the Cinema Tour data in Tableau
Now we can start building the vizzes shown in the main demo of the Tableau Cinema Tour! These are the first two – the German originals:

Tableau Cinema Tour: Number of Movies per Decade

Tableau Cinema Tour: Budget vs. Box Office
What’s next?
We downloaded the IMDb, parsed it, and saved it into a PostgreSQL database. We also extracted a subset of the data and did some post-processing on it. The result is exactly the data set used in the Tableau Cinema Tour. Of course did a lot of other things in preparation for the Cinema Tour, but that would make this blog post even longer than it already is. If you want to see what else can be done with these data, just make sure to come by when the Tableau Cinema Tour hits your town!
I’ve been trying to run the script but it keeps giving me an error on line 246:
print “executescript [status] : executing query:\n\t%s\n” % (query.strip())
^
SyntaxError: invalid syntax
I was hoping you could help me resolve this issue. Thanks!