
With the integration of external services such as R, Python, and MatLab into Tableau you can significantly broaden the circle of possible users for your organization’s data science models and workflows, by embedding them into easy-to-use dashboards that are appealing to all types of consumers. That said, if you have ever worked with the integration of external services in Tableau, you will be aware that you can only define one service connection per workbook at a time – either to RServe or to TabPy. The first time this fact became painfully apparent to me was during a workshop where I was showing the integration with both services. Every single time I switched from a worksheet that employed some R code to one embedding Python code, I had to set the connection to RServe. Whenever I moved back over to another worksheet with some embedded Python code, I first ran into an error (since Tableau sent the Python code to RServe, which obviously made the R session choke) and then had to manually reset the connection to TabPy. The same was true for the session “R … You Ready for Python?” me and my colleague Lennart Heuckendorf delivered at Tableau Conference Europe 2018 and 2019. Even worse, I am more and more working with customers whose data science stack is very diverse, so they are using models in all kinds of languages. For them it is imperative to be able to run both R and Python models within the same dashboard, possibly even on one single worksheet. So I was wondering: can this be done?
tl;dr: It’s absolutely possible! This article outlines the process we suggest and guides you from zero to a working environment to do exactly this. It builds heavily on an idea proposed by my colleague Timo Tautenhahn and one of his customers here and here, so I can’t take all the credit. It also makes use of a number of external and open source software packages, so this is neither officially supported by Tableau (don’t try logging a ticket with Technical Support if this doesn’t work for you) nor is this an official Tableau tutorial. If all these caveats didn’t discourage you to try it out yourself, read on! All the code required or referenced here is available on my GitHub repository. Also, you’ll find a video at the end of this blog post to walk you through the full process.
The basics
I decided to implement this on a Ubuntu Linux 16.04 machine, but it should work on Windows as well – let the rest of us know if you managed to do that. The following schema outlines the approach: instead of connecting Tableau (Desktop or Server doesn’t matter – here, I will only show it for Desktop, though) directly to RServe and/or TabPy we will use an intermediary stage that redirects the service calls to either R or Python, based on a service identifier we need to send to it as well. For the purpose of this example implementation, I decided to implement that forwarder stage in Python, but you could as well do it in R if you fancy that – again, please share your experiences. This External Services Proxy (as I’m calling it) script is running in Python in a TabPy session which we can directly hook up to Tableau. On the receiving end we have to provide running R and Python sessions, both eagerly waiting for the code and data you sent from Tableau. There are multiple options to achieve this, but I opted for the two most commonly used and most actively developed packages: plumber for R and Flask for Python. Both create API endpoints to their respective interpreters that can be sent JSON objects with all the code and data, and will also send back JSON objects when done.
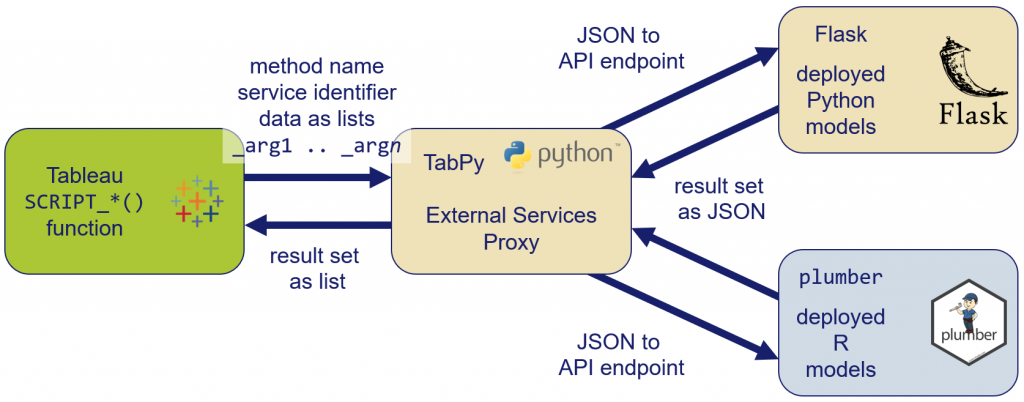
Let’s now walk through the setup of this contraption, step-by-step. Note, that for the purpose of this blog post and also for simplicity I opted to install all three instances (TabPy, Flask, and plumber) on the same machine. I would highly advise against that in a production environment, as otherwise they will battle for hardware resources which might lead to contention.
Setting up R: plumber
This is the easier of the two. It should be as simple as installing R on some machine. I will not explain the details here, as there are many tutorials to be found online.
sudo apt-get update sudo apt-get install r-base
Next we need to install the plumber packages, which can also be achieved very easily inside an R console:
install.packages("plumber")
Done!
Setting up Python: Flask
This one is a bit more tricky, and since I am running the two Python endpoints (Flask and TabPy) on the same machine, I decided to use two separate Anaconda environments for them. Again, I’m not going to explain the details on how to install and setup Anaconda, as there are plenty instructions and tutorials on that to be found online.
cd /tmp curl -O https://repo.anaconda.com/archive/Anaconda3-2019.07-Linux-x86_64.sh bash Anaconda3-2019.07-Linux-x86_64.sh source ~/.bashrc
We will create a fresh Anaconda environment for Flask and install it into that:
conda create --name flask python=3 conda activate flask pip install Flask
Done!
Setting up TabPy
TabPy will also run inside an Anaconda environment:
conda create --name tabpy python=3 conda activate tabpy pip install tabpy-server
Unfortunately, the current version of TabPy installed by pip comes with an unsupported, too new version of the tornado library. This becomes evident when trying to test run the freshly installed instance:
cd anaconda3/envs/tabpy/lib/python3.7/site-packages/tabpy_server ./startup.sh
Which generates the following output:
(tabpy) kgreger@vm:~/anaconda3/envs/tabpy/lib/python3.7/site-packages/tabpy_server$ ./startup.sh
Using initial state.ini
Traceback (most recent call last):
File "/home/kgreger/anaconda3/envs/tabpy/lib/python3.7/site-packages/tabpy_server/tabpy.py", line 279, in
class EndpointsHandler(ManagementHandler):
File "/home/kgreger/anaconda3/envs/tabpy/lib/python3.7/site-packages/tabpy_server/tabpy.py", line 287, in EndpointsHandler
@tornado.web.asynchronous
AttributeError: module 'tornado.web' has no attribute 'asynchronous'
But fear not, the solution is as simple as downgrading the version of the tornado library like this – the first command should reveal the currently installed version, most likely 6.0.3:
pip list pip install Tornado==5.1.1 ./startup.sh
After this you will see the TabPy session running and listening on default port 9004:
(tabpy) kgreger@vm:~/anaconda3/envs/tabpy/lib/python3.7/site-packages/tabpy_server$ ./startup.sh Found existing state.ini Initializing TabPy… Done initializing TabPy. Web service listening on port 9004
This TabPy session can now be accessed directly from Tableau. After this successful test, let’s shutdown the TabPy session until later – easiest by pressing Ctrl & C.
The models
For the purpose of this explanatory blog post, I decided to keep things simple and have two “models” in R and Python that simply output any string they’re being sent, together with a nice little message.
R
The code in R is pretty straight-forward, only the plumber syntax might seem a little weird in the beginning. Here’s the full file, we’ll walk though it line-by-line:
# myModel.R
#' Make R write a message
#' @param message The message to echo back.
#' @post /r_says_hello
#' @serializer unboxedJSON
function(message="Hello!"){
return(list(result = paste0("R says: ", message)))
}
The actual “model” is contained in an anonymous function, which in this case takes one argument message. All that function does is taking the string, prepending it by “R says: ” and converting it into a list, only to return that.
The more interesting part is what appears to be comments before the actual code. This is the syntax of telling plumber what to do and how the API endpoint for this function will be called. @post defines the name of the endpoint, here r_says_hello, while @serializer tells plumber which format to send the payload in, here JSON – as this is what TabPy expects.
Save this code into a file called myModel.R, and – for now – just put it in the home directory.
Python
Flask uses a similar approach as we just saw with R and plumber. Here’s the full “model”:
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/python_says_hello', methods=['POST'])
def python_says_hello(message = 'Hello!'):
message = 'Python says: {}'.format(request.form['message'])
return jsonify(result=message)
In Flask terms, the API endpoints are called apps. The @app.route() method here defines an app called python_says_hello that uses HTTP POST to transfer data. JSON is the default format, so no need to specify that. Before running the actual code inside the function python_says_hello() (same name as the API endpoint!), we need to load some libraries: Flask itself, request to handle the HTTP requests, and jsonify to parse the result into JSON. The function itself is as simple as the one we saw with R earlier, prepending the one string parameter it’s given by “Python says: ” and then JSONifying it.
Save this code into a file called myModel.py and once again just put it in the home directory.
Deploying
Since both plumber and Flask hog their respective terminal sessions, I personally like to run each of them in a separate one. Feel free to use GNU screen or whatever method you prefer to do that.
plumber
As for R and plumber, deploying the model is as easy as running the following code inside an R session on the machine we just installed plumber on:
library(plumber)
r <- plumb('/home/kgreger/myModel.R')
r$run(port=6313)
Note how I opted for port 6313 instead of the default RServe port of 6311 to avoid confusion. This means you could also run an additional standalone RServe session on that very same machine. You will most likely have to modify the path to your myModel.R file.
Starting server to listen on port 6313 Running the swagger UI at http://127.0.0.1:6313/__swagger__/
Perfect!
Flask
With Python and Flask the process is not much different, we just run the following code on the machine we just installed Flask on:
conda activate flask FLASK_APP=/home/kgreger/myModel.py FLASK_DEBUG=1 python -m flask run
As I did not specify a port here, Flask’s default port of 5000 will be used. Again, please make sure to modify the path to your myModel.py file.
* Serving Flask app "/home/kgreger/myModel.py" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: on * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 356-819-137
Perfect! (Take note of the warning regarding the use in a poduction system and move on.)
The External Services Proxy
Now come the magic parts! As a last step we need to implement and deploy the code to the TabPy session we will hook up directly with Tableau. The code looks like this:
import tabpy_client
client = tabpy_client.Client('http://127.0.0.1:9004')
def external_services_say_hello(message, service):
import requests
if service == 'PYTHON':
r = requests.post('http://127.0.0.1:5000/python_says_hello', data = {
'message': message})
elif service == 'R':
r = requests.post('http://127.0.0.1:6313/r_says_hello', data = {
'message': message,})
serviceResult = r.json()
return serviceResult['result']
client.deploy('external_services_say_hello', external_services_say_hello, 'Make Python or R say Hello or anything you want.', override = True)
print('*** Model deployed successfully ***')
Note how we’re employing the tabpy_client library coming with TabPy, and connect it to the TabPy session running on the same machine on port 9004 on the second line. The method external_services_say_hello() is the main bit, taking both a string parameter messages and another one called services. While the first is our actual data, the second is the service identifier we use to tell the script whether the data should be sent to the model in R or Python. Using the requests.post() method from the request library the script does exactly that, depending on the contents of the service parameter.
We’re referencing both services running on the separate ports we defined in the previous deployment steps (5000 for Flask; 6313 for plumber) and by the API endpoint names we set earlier in the myModel.* files. The result of both API calls is coming back as JSON, which is just sent back to Tableau. (Hint: That’s why we had to make it a list at the end of our R code.) Finally, we’re deploying the function external_services_say_hello() to tabpy_client using the penultimate line. It’s now available on our TabPy instance.
Lastly, we have to fire it up so it can start taking our requests from Tableau and forwarding them to R and Python, respectively. We do this by first starting up the TabPy session, listening on default port 9004:
conda activate tabpy cd ~/anaconda3/envs/tabpy/lib/python3.7/site-packages/tabpy_server/ nohup ./startup.sh 0<- >/dev/null &
The cryptic last line only makes sure to run TabPy in a headless session so we don’t need an extra terminal session for the next command. It also returns the process ID (pid) of the TabPy session, useful in case you want to kill it later:
[1] 82403
Lastly we deploy the External Services Proxy model to the TabPy session:
python deploy_external_services_proxy_to_tabpy.py
Using
So now the time has come to use our External Services Proxy in real life, that is directly from Tableau. All we need for this is a workbook that sends some text and expects back our friendly messages from either R or Python. An easy way to achieve this is to load the Superstore data that comes with Tableau Desktop, put the [Region] pill on Rows and then let the message display afterwards.
The syntax for using models that have been deployed into a TabPy session is a bit different than the usual way, where we use a SCRIPT_*() function and submit the code with embedded _argn references, plus the data as a list of field names. Instead, we use the following syntax:
SCRIPT_STR("
return tabpy.query('external_services_say_hello', _arg1, 'R')['response']
",
MAX([Region]))
As you can see the basic principle is the same, only instead of including all the code (which makes it very cumbersome to correct or maintain across possibly hundreds of workbooks) we are only calling the function we deployed earlier into the TabPy session, here external_services_say_hello, provide the data, and ask only for the response object of the data the function returns.
Et voilá:
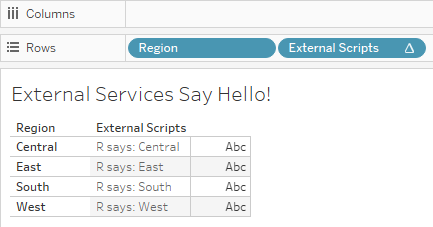
Note how the first argument for the tabpy.query() method is the function name (which also means you can deploy many of those into your TabPy session!), the second is the data, and the last one is our trusty service identifier. Try changing it from “R” to “PYTHON” and watch the output.
What’s next?
Obviously, your first next step should be to implement your actual data science models instead of the toy “models” we used here.
Another idea is to leverage a Parameter in Tableau to switch between the two languages. To do so, the Calculated Field has to be modified slightly:
SCRIPT_STR("
return tabpy.query('external_services_say_hello', _arg1, '" + [Service] + "')['response']
",
MAX([Region]))
The same trick can be used to allow the end user to switch between multiple models. Just note that the string value returned by the Parameter has to be embedded as a literal string into the SCRIPT_*() function call, we can’t use the normal _argn notation here.
For debugging purposes it might make sense if your models produce some output on their respective console (or a log file). Here’s an example of what that could look like for our R model:
# myModel.R
#' Make R write a message
#' @param message The message to echo back.
#' @post /r_says_hello
#' @serializer unboxedJSON
function(message="Hello!"){
print(paste0(Sys.time(), ": ", message))
return(list(result = paste0("R says: ", message)))
}
Who doesn’t love terminal windows with messages appearing like magic? (OK, maybe that’s just me…)
Due to the flexible nature of how the scripts are run only on request it’s also very easy to modify them without having to go back and make changes to the workbooks or calculations inside of Tableau (unless your API changes…). All you have to do is redeploy them to their respective service (plumber or Flask) by stopping and restarting these with a reference to the updated model file (myModel.R or myModel.py in the example above). In reality this can mean a downtime of only a few seconds – your users won’t even notice.
Let us know what else you came up with and maybe tell us if and how you used this in your production use! Also, please feel free to point out obvious mistakes I made or if and how the code can be optimized. All the files are in my GitHub repository, so fork away!
Thanks for the shout out! Good write up. Posts like this really help preppie contribute and understand the flow of the project.