Im letzten Quartal 2016 haben wir als würdigen Nachfolger der Tableau Stadion Tour 2015/16 die Tableau Kino Tour 2016/17 aus der Taufe gehoben. Nach vier bisher sehr erfolgreichen Stationen (Frankfurt, Hamburg, Berlin und Düsseldorf) warten jetzt im zweiten Teil der Tour in 2017 noch Wien, München, Zürich und Stuttgart auf uns. Da immer wieder die Frage nach den Daten kam, die hinter der Kino Tour stecken, und auch weil es tatsächlich ein sehr interessantes und spaßiges Projekt war, diese Daten zu generieren, habe ich im Folgenden mal die einzelnen Schritte zusammengefasst, vom Download der Quelldaten bis zum fertigen Produkt. Aus Copyright-Gründen dürfen wir die fertigen Daten leider nicht einfach so zum Download anbieten, aber mit der Schritt-für-Schritt-Anleitung sollte es nicht allzu schwierig sein, das zuhause selbst nachzustellen.

Tableau Kino Tour
Werkzeuge
- Die Sammlung der Daten bzw. die Extraktion verwertbarer Informationen aus den Quelldateien geschieht mittels Python-Skripten. Ich gehe im Folgenden davon aus, dass bereits ein lauffähiges Python 2.7 (mit Python 3 habe ich die Skripte noch nicht getestet) vorliegt. Wie man das zum Fliegen bringt behandle ich hier nicht, es gibt aber zahlreiche Anleitungen im Internet. Die aktuellste Version von Python 2.7 steht hier zum Download bereit.
- Zum Extrahieren der Quelldateien ist ein Tool nötig, das mit
.gz-Dateien umgehen kann. Auf Linux-Systemen kann dafür bspw.gzipodergunzipverwendet werden, bei Windows empfehle ich 7zip – das kommerzielle WinZip kann in neueren Versionen ebenfalls mit diesen Archiven umgehen. - Das Hauptskript schreibt die Daten direkt in eine PostgreSQL-Datenbank. Es wird also Zugang zu einer Postgres-Datenbank benötigt. Die Standardkonfiguration der Skripte geht von einer lokalen Installation aus (die Datenbank läuft also auf demselben Rechner wie das Skript), aber eine Remote-Datenbank funktioniert natürlich auch. Die aktuellste Version von PostgreSQL steht hier zum Download bereit. Ich arbeite aktuell mit Version 9.5 aber 9.6 sollte kein Problem darstellen.
- Als Editor für die Skripte nutze ich Notepad++, aber jeder beliebiger Texteditor ist gut genug. Wahlweise geht auch eine richtige Python-IDE wie Spyder. Zum Überprüfen oder Bearbeiten der teilweise doch sehr großen Quelldaten nutze ich Sublime, weil er auch gut mit sehr großen Dateien umgehen kann.
- Zur bloßen Nutzung der Skripte wird das nicht mehr notwendig sein, aber bei der Entwicklung der Skripte und dem Bau der darin exzessiv verwendeten regulären Ausdrücke hat mir die Website regex101.com sehr gute Dienste geleistet. (Tipp: Nicht vergessen, links bei “Flavor” auf “Python” umzustellen…)
- Und dann brauchen wir selbstverständlich Tableau, um die Daten auch zu visualisieren!
Die Quelldaten
Die Daten zur Tableau Kino Tour kommen aus der wohl bekanntesten und umfangreichsten Quelle für alles, was mit Kino, Film und Fernsehen zu tun hat: Der Internet Movie Database (IMDb). Eigenen Angaben zufolge enthält die IMDb in dem Moment, da ich das schreibe, Daten zu 4.056.313 Produktionen und 7.654.857 Personen. Natürlich könnte man jetzt hergehen und per Webcrawler die komplette IMDb herunterladen. Das würde aber gegen die Nutzungsrichtlinien der Site verstoßen und wäre vermutlich auch nicht sehr performant. Zudem ändern sich die Daten in der IMDb so schnell, dass dabei vermutlich inkonsistente Daten herauskämen.
IMDb
Viel einfacher ist es deshalb, die komplette IMDb auf einmal herunterzuladen! Leider ist das komplette Datenmodell der zugrunde liegenden Datenbank nicht einfach so verfügbar – das wäre ja auch zu schön und würde diesen Artikel überflüssig machen! Gut versteckt unter der Überschrift “Alternative Interfaces” (apropros: Die IMDb ist prinzipiell auf Englisch, es gibt allerdings teilweise lokalisierte Titel) lassen sich aber “Plain Text Data Files” herunterladen. Ich persönlich nutze hierfür den Mirror der FU Berlin – an dieser Stelle mein Dank an die anonymen Betreiber!
Es gibt übrigens eine Umfrage der IMDb-Betreiber zum Aufbau einer IMDb-API. Wer sich hierfür interessiert oder hierzu etwas beizutragen hat, sei auf die dazugehörige Seite verwiesen.
Der Workflow
Einleitung
Der folgende Abschnitt ist teilweise recht technisch. Um das Skript verwenden zu können, ist es allerdings nicht notwendig, alles bis ins letzte Detail zu verstehen – also keine Sorge, wenn der ein oder andere Begriff unbekannt sein sollte!
Die Grundlage des Skriptes, das ich hier vorstelle, stammt ursprünglich von Ameer Ayoub und steht auf seinem GitHub-Repository zum Download bereit. Das Skript liest die Quelldateien ein, parst sie in ein sinnvolleres Format und speichert das Ergebnis in eine Datenbank. Klingt erstmal recht einfach, ist es aber nicht, wie u.a. die Länge des Quellcodes zeigt. Ameer hat aber exzellente Arbeit geleistet und das Skript sehr sauber und nachvollziehbar, dabei aber gleichzeitig flexibel und leicht erweiterbar geschrieben. Ich habe also sein Repository geforkt und dann lokal weiterentwickelt. Dabei hatte ich allerdings im Gegensatz zu Ameer weniger die universelle Wiederverwendbarkeit des Codes im Kopf als vielmehr den Einsatz für meinen, ganz genau umrissenen Anwendungsfall im Rahmen der Tableau Kino Tour. Das bedeutet, dass ich es zwar einerseits um die Themen Bewertungen, Geschäftszahlen, Drehorte und biographische Daten erweitert habe, diese Anpassungen aber nur für PostgreSQL als Backend implementiert habe. Falls also jemand das vorliegende Skript mit einer MySQL- oder SQLite-Datenbank einsetzen will, wäre hier noch einiges an Nacharbeiten bei den Schemabeschreibungen usw. notwendig. Für Postgres funktioniert aber alles out-of-the-box.
Schritt 0: Vorbereitungen
Alle oben genannten Tools (oder alternative, bevorzugte Produkte) sollten installiert und getestet werden. Die Python-Installation lässt sich am einfachsten testen, indem auf einer Kommandozeile python eingetippt wird. Das Ergebnis sollte aussehen wie folgt:

Python-Test (Windows)
Der Weg aus der Python-Kommandozeile (erkennbar am >>>) führt wie gezeigt über die Eingabe des Befehls exit(). Alle Beispiele in diesem Artikel werden übrigens anhand von einem Windows-System gezeigt, das ganze funktioniert aber prinzipiell plattformunabhängig, also auch auf OS X macOS oder Linux.
Schritt 1: Das Skript herunterladen
Das von mir modifizierte Skript liegt auf meinem GitHub-Repository und kann von dort entweder geforkt, geklont oder einfach als ZIP-Datei heruntergeladen werden.

GitHub: Repository klonen oder herunterladen
Schritt 2: Die Quelldaten herunterladen
Die IMDb-Daten selbst lassen sich sehr einfach vom o.g. FTP-Server der FU Berlin herunterladen:
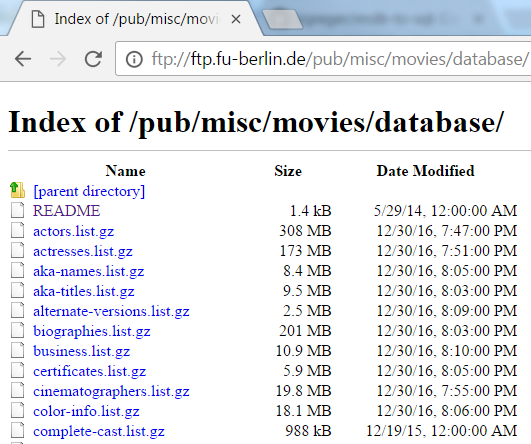
IMDb-Dateien auf dem FTP-Server der FU Berlin
Es handelt sich dabei um gezippte Text-Dateien mit der Dateiendung .list. Das Skript verwendet in der aktuellen Version nur folgende Dateien:
actors.list.gzactresses.list.gzbiographies.list.gzbusiness.list.gzlocations.list.gzmovies.list.gzratings.list.gz
Für den möglichst reibungslosen Einsatz des Skripts (sprich: mit möglichst wenigen Änderungen) empfehle ich, diese Dateien in einen Unterordner des eigentlichen Skripts zu speichern, idealerweise sollte dieser imdb-list heißen. (Hinweis für GitHub-Nutzer: Der Unterordner imdb-list sollte dann in die .gitignore aufgenommen werden, da sonst die kompletten IMDb-Daten auf GitHub gepusht würden…) Dort können sie dann entpackt und die .gz-Dateien anschließend gelöscht werden:
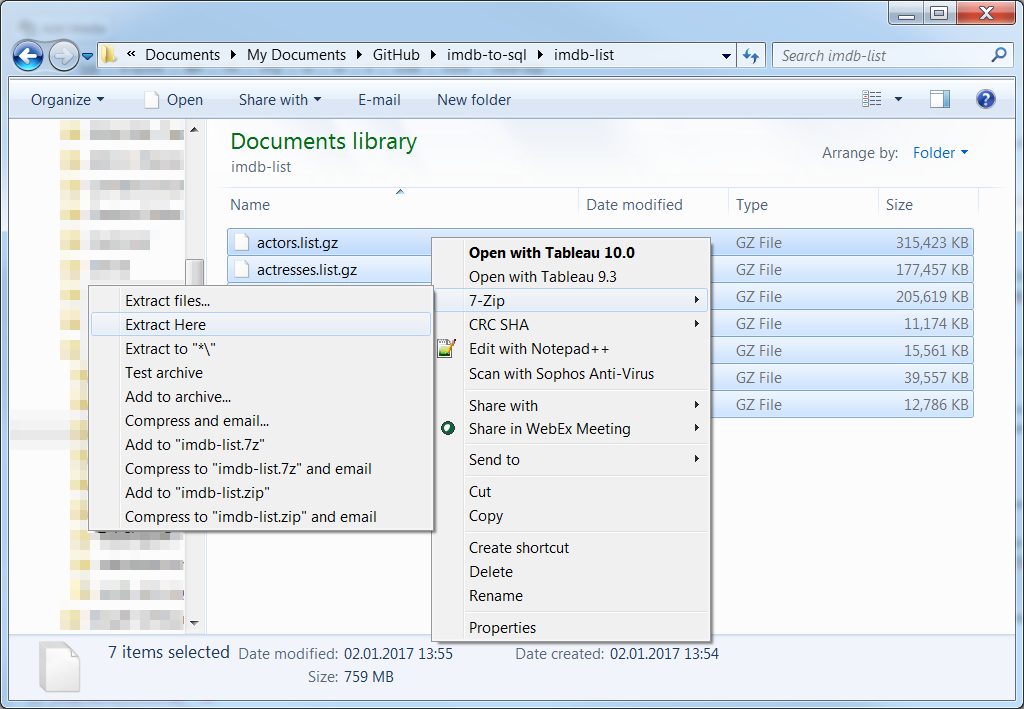
.gz-Dateien mit 7zip extrahieren
Zudem müssen die Dateien noch vom Zeichensatz ISO-8859-1 (“Latin-1”) in UTF-8 umgewandelt werden. Das geschieht am einfachsten im Texteditor der Wahl, bei Sublime bspw. über File > Save with Encoding > UTF-8, bei Notepad++ über zunächst Encoding > Convert to UTF-8 und dann über File > Save.

Speichern mit anderer Codierung in Sublime
Schritt 3: Das Skript anpassen
Das ist der vermutlich komplizierteste Schritt – ist aber eigentlich auch nicht weiter wild, sofern oben überall die Standardeinstellungen beibehalten bzw. meinen Empfehlungen nachgekommen wurde. Auf jeden Fall kann es sein, dass das Skript mehrfach angepasst werden muss, bevor es fehlerfrei durchläuft. Aber keine Sorge, man kann hier nichts kaputt machen.
Was ich bisher immer mit “das Skript” umschrieben habe, ist eigentlich eine Sammlung aus Python-Quellcode (erkennbar an der Dateiendung .py) und SQL-Code (erkennbar an der Dateiendung .sql im Unterordner schemas). Sowohl der Programmcode als auch die Abfragen sind durchgehend und relativ ausführlich kommentiert. Geneigte Leser sollten sich also in relativ kurzer Zeit in die Funktionsweise einlesen können – das ist aber zum Einsatz absolut nicht notwendig.
Die zentrale Komponente ist die Datei tosql.py. Hier findet sowohl das Einlesen der Textdateien als auch das Parsen der Informationen mittels regulärer Ausdrücke und das Abspeichern in die Datenbank statt. Die Datei settings.py beinhaltet, wie der Name vermuten lässt, die wesentlichen Einstellungen für das Skript. Des Weiteren werden aus dem Skript heraus im Unterordner schemas die Dateien postgres.drop.sql und postgres.use_dict.sql zum Initialisieren der Tabellen in der Datenbank aufgerufen. Die Dateien postgres.index.sql und postgres.postprocess.sql führen wir abschließend noch manuell aus.
Am sinnvollsten ist es, zunächst die Basiseinstellungen in der Datei settings.py vorzunehmen. Standardmäßig sieht diese aus wie folgt:
class DatabaseTypes: SQLITE = 0 MYSQL = 1 POSTGRES = 2 # script configuration # database options class Database: type = DatabaseTypes.POSTGRES# database type, one of DatabaseTypes database = "imdb_data" # database name encoding = "utf-8" # used to pre-encode the queries to drop any invalid characters # for the database type host = "127.0.0.1" # database host user = "postgres" # database username password = "postgres" # database password clear_old_db = True # clear old database information if exists # general options class Options: list_dir = ".\imdb-list" # directory of the imdb list files file_extension = ".list" # file extension for the imdb list files query_debug = False # show log of all sql queries at construction time show_progress = True # show progress (at all) progress_count = 10000 # show progress every _n_ lines commit_count = 10000 # commit every _n_ lines, -1 means only on completion # database will commit on completion of each file regardless show_time = True # show the total time taken to complete use_native = False # use native parsing operations instead of regex use_dict = True # use a dictionary to generate and cache db id's in program use_cache = False # cache the dictionaries to the disk, must be enabled if you # you want to convert only some files and you want to use dict schema_dir = "schemas" # directory to load the db schemas from cache_dir = "cache" # directory to load the dictionary caches from if applicable proc_all = True # overrides the individual process directives
Hervorgehoben sind hier die Teile, die auf jeden Fall überprüft und gegebenenfalls angepasst werden müssen:
- Zeile 10 enthält den Namen der Datenbank, die wir in PostgreSQL anlegen – standardmäßig
imdb_data. - Zeile 13 enthält die Adresse des Datenbankservers – standardmäßig
127.0.0.1für einen lokalen Server. - Zeilen 14 und 15 enthalten die Zugangsdaten zur Datenbank.
- Zeile 16 legt fest, ob beim Start des Skripts eine bereits bestehende Datenbank geleert werden soll. Das ist prinzipiell nicht weiter tragisch, kann aber bei kleineren Tests unter Umständen lange Laufzeiten zur Folge haben. Standardeinstellung ist hier
True - Zeile 20 enthält den Pfad, in dem das Skript die Quelldateien erwartet – standardmäßig wie oben beschrieben der Unterordner
imdb-list.
Zudem kann es unter Umständen interessant sein, das Flag query_debug auf True zu setzen, sofern eine sehr detaillierte Ausgabe der einzelnen Aktivitäten gewünscht wird. Die Performance geht dabei aber natürlich absolut in den Keller – das ist damit also nur für Tests geeignet. Die Optionen progress_count und commit_count legen fest, nach jeweils wie vielen Zeilen der Eingangsdaten eine Statusmeldung ausgegeben werden soll bzw. die Daten in die Datenbank geschrieben werden sollen. Bei letzterem sorgt eine Einstellung von -1 dafür, dass das Ergebnis erst ganz am Ende jeder Quelldatei gespeichert wird. Das führt allerdings zu einem massiv erhöhten Speicherverbrauch, daher rate ich eher davon ab. Zu guter Letzt kann mittels des Parameters proc_all sichergestellt werden, dass alle Quelldateien abgearbeitet werden. Sollte dieser Parameter auf False stehen, wird in den Zeilen 497-504 des Skripts tosql.py festgelegt, welche Dateien bearbeitet werden. Auch dies ist allerdings eher für Test- und Entwicklungszwecke gedacht:
process_flags = {
"people": False,
"productions": False,
"ratings": True,
"business": True,
"locations": True,
"biographies": True
}
Schritt 4: Die Datenbank vorbereiten
Die PostgreSQL-Datenbank, in die das Skript die Ausgabedaten schreiben soll, muss vor dem Start des Skripts noch angelegt werden. Das lässt sich am einfachsten mit einer grafischen Benutzeroberfläche wie pgAdmin (wird entweder bei der PostgreSQL-Installation mitinstalliert, oder von der Website herunterladen) erledigen, geht aber genauso gut auch auf der Kommandozeile. Hier habe ich den Datenbanknamen imdb_data gewählt, was zur Folge hat, dass die Einstellungen des Skripts (s.o.) nicht verändert werden müssen. Ansonsten muss in Zeile 10 der Datei settings.py der korrekte Datenbankname angegeben werden. Wichtig ist zudem, dass der Eigentümer der Datenbank mit dem in Zeile 14 der Datei settings.py übereinstimmt – hier bspw. postgres.
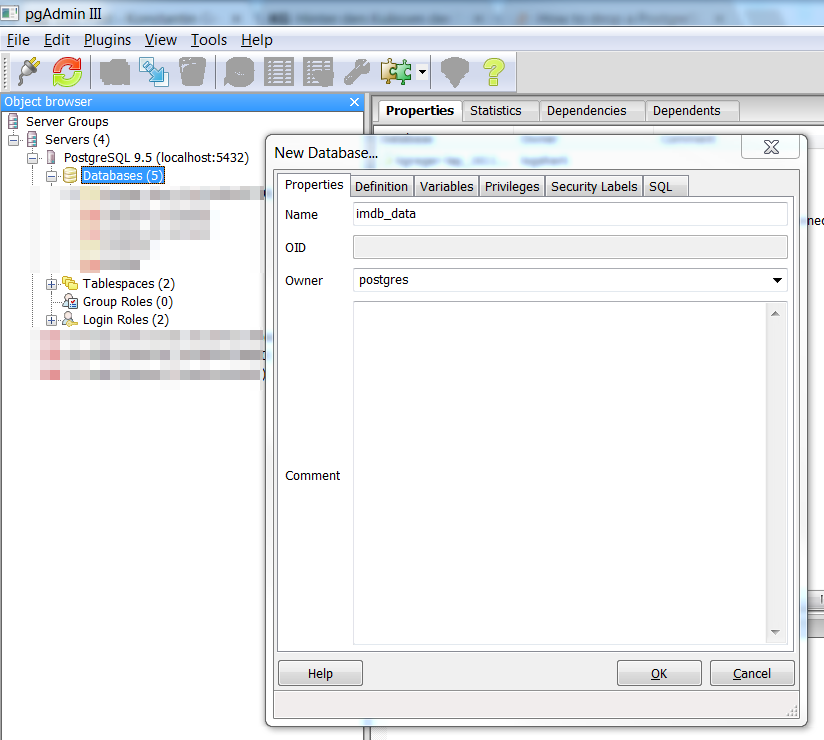
Erstellen einer neuen Datenbank in pgAdmin III
Das daraus resultierende SQL-Statement lautet:
CREATE DATABASE imdb_data
WITH ENCODING='UTF8'
OWNER=postgres
CONNECTION LIMIT=-1;
Schritt 5: Das Skript ausführen
Wenn alle Vorbereitungen getroffen sind, kann es eigentlich losgehen! Das Hauptskript wird durch die Eingabe von python tosql.py auf der Kommandozeile gestartet. Dazu müssen wir uns natürlich im richtigen Ordner befinden, ansonsten muss der Pfad mit angegeben werden.
Der Code selbst ist nicht sonderlich effektiv oder performant geschrieben, deshalb dauert die Ausführung eine Weile – zuletzt auf meinem nicht allzu schwachen Rechner knapp 5,5 Stunden. Aber, alte Programmierer-Regel: Wenn die Implementation der Optimierung mehr Zeit in Anspruch nimmt, als letztlich durch den optimierten Code eingespart wird, lohnt sich der Aufwand nicht. Zumal wir dieses Skript ja in aller Regel nur ein einziges Mal laufen lassen…
Zwischendurch werden einige Warnungen ausgegeben:

Warnung des Skripts tosql.py
Diese können aber getrost ignoriert werden. Es handelt sich hierbei um Datensätze, die aufgrund von Sonderzeichen (meistens Anführungszeichen) nicht korrekt von den regulären Ausdrücken geparst werden konnten. Diese Daten fehlen später zwar im Datensatz, aber auch hier galt wieder die oben schon angeführte Regel zur Abwägung zwischen Aufwand und Ergebnis… Die RegEx sind in der aktuellen Form schon komplex genug – vielleicht möchte sich ja ein/e geneigte/r Leser/in mal daran versuchen?
Die Ausführung des Skripts endet mit der Ausgabe der Gesamtlaufzeit in Sekunden:
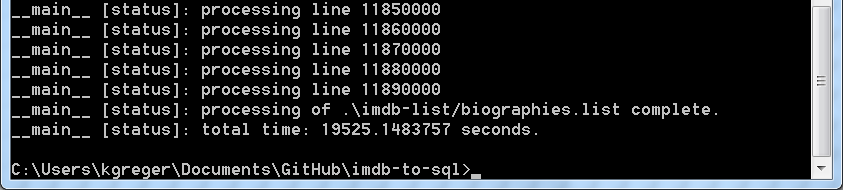
Zusammenfassung am Ende des Skripts tosql.py
Schritt 6: Indizes anlegen und Daten weiterverarbeiten
Indizes helfen uns hinsichtlich der Performance der IMDb-Daten, die jetzt nach erfolgreicher Ausführung des Haupt-Skripts in unserer PostgreSQL-Datenbank liegen. Zum Erstellen der Indizes nutzen wir einfach das Skript index.py über den Aufruf python index.py auf der Kommandozeile:

Ausführen des Skripts index.py auf der Windows-Kommandozeile
Für die weiteren Datenverarbeitungsschritte habe ich kein Python-Skript erstellt, diese erledigen wir also direkt in der PostgreSQL-Datenbank, am einfachsten mittels einer graphischen Benutzeroberfläche wie pgAdmin. Die Schritte selbst habe ich in der Datei postgres.postprocess.sql im Unterodner schemas zusammengefasst. Dieses lässt sich in pgAdmin ganz einfach komplett in einem Rutsch ausführen:
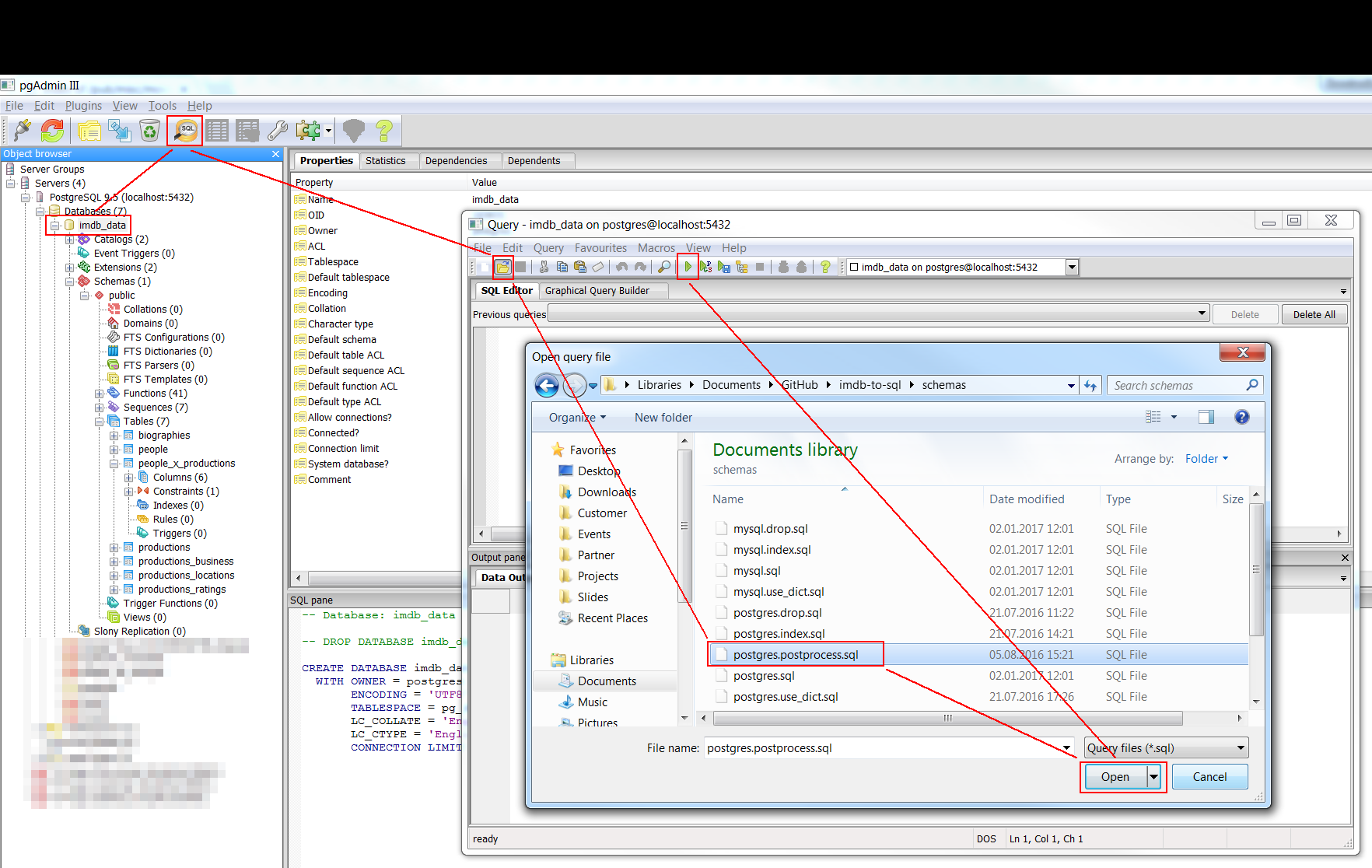
Ausführen einer Abfrage aus einer .sql-Datei in pgAdmin III
Nach der Verbindung auf die korrekte Datenbank (hier bspw. imdb_data) ein Klick auf den Abfrage-Button oben, dann im sich neu öffnenden Abfragefenster auf den Öffnen-Button, die richtige Datei auswählen (hier bspw. postgres.postprocess.sql) und schließlich ein Klick auf den Ausführen-Button mit dem grünen Pfeilsymbol.
Kommandozeilen-Freaks können das selbstverständlich auch per psql -U postgres -d imdb_data -a -f postgres.postprocess.sql erledigen – dafür sollte der Pfad zu den PostgreSQL-Binaries (C:\Program Files\PostgreSQL\VERSION\bin) bevorzugterweise in der PATH-Umgebungsvariable stehen. Die kursiv gesetzten Teile müssen u.U. angepasst werden.
Wer mit den Rohdaten der IMDb arbeiten möchte, sollte dieses Skript postgres.postprocess.sql nicht ausführen – hierbei handelt es sich nur um Vorarbeiten im Rahmen der Tableau Kino Tour.
Schritt 7: Fertig!
Damit liegen die kompletten Daten der IMDb (jedenfalls die Teile, die wir heruntergeladen haben) in unserer PostgreSQL-Datenbank vor, sind schön nutzbar aufbereitet, umfassend indiziert und damit fertig für den Einsatz in Tableau! Auch wenn ich aus Performancegründen davon abrate, so sieht das komplette Datenmodell aus:

Komplettes Datenmodell aus imdb_data in Tableau
Für die Kino Tour benötigen wir allerdings gar nicht dieses komplexe Datenmodell – hier geht es ja zunächst nur um die einzelnen Produktionen. Das Skript postgres.postprocess.sql hat die Daten aus der Tabelle biographies direkt an die einzelnen Personen in people angespielt sowie die jeweils aktuellsten Produktionskosten und weltweiten Einspielergebnisse in US-Dollar aus business an die Produktionen in productions angefügt. Zudem habe ich noch einige sehr grobe Filter für offensichtliche Datenfehler eingebaut: Personen, die im Alter von unter 0 oder über 120 Jahren einen Film produziert haben sowie Produktionen, die weniger als 0 oder mehr als 350 Millionen US-Dollar gekostet bzw. weniger als 0 oder mehr als insgesamt 2,8 Milliarden oder am Eröffnungswochenende 250 Millionen US-Dollar eingespielt haben. Diese Obergrenzen müssen u.U. irgendwann nach oben korrigiert werden, passen aber derzeit noch. Zudem habe ich alle Produktionen gelöscht, die nicht entweder als Film oder (Episode einer) Fernsehserie gekennzeichnet sind, also bspw. Computerspiele, DVDs und dergleichen.
Allerdings sind die Feldnamen in der Datenbank teilweise doch noch etwas kryptisch bzw. es fehlen einige der im Rahmen der Tableau Kino Tour verwendeten Felder. Abhilfe schafft hier die Tableau-Datenquelle Tableau Kino Tour.tds (Rechtsklick > Ziel speichern unter...). Hier wird außerdem nur die Tabelle productions verwendet – mit mehr haben wir uns im Kontext der Kino Tour nicht beschäftigt. Beim Laden der .tds-Datei wird Tableau nach dem Namen und Passwort des PostgreSQL-Datenbankanwenders fragen (hier bspw. postgres/postgres). Sollte zudem die PostgreSQL-Datenbank nicht auf dem lokalen Rechner laufen, ist es notwendig, die Verbindungsparameter über die Option Verbindung bearbeiten zu definieren.
Verbindung zur imdb_data-Datenbank herstellen
Verbindungsparameter zur imdb_data-Datenbank bearbeiten
Um eine zufriedenstellende Performance zu erhalten, erstellen wir abschließend noch aus den PostgreSQL-Daten einen Tableau-Datenextrakt (.tde-Datei). Das geht einfach über einen Rechtsklick auf die Datenquelle “Tableau Kino Tour” links oben > Daten extrahieren... und dann einen Klick auf den Button “Extrahieren” im sich neu öffnenden Dialogfenster.

Extrahieren der Kino Tour-Daten in Tableau
So können wir jetzt unsere ersten Datenvisualisierungen erstellen. Hier exemplarisch die ersten beiden aus der Kino Tour:

Tableau Kino Tour: Filme je Jahrzehnt

Tableau Kino Tour: Budget vs. Einspielergebnis
Was nun?
Damit haben wir jetzt die IMDb heruntergeladen, geparst und in eine PostgreSQL-Datenbank gespeichert. Zudem haben wir eine Teilmenge davon noch weiter nachbearbeitet. Damit liegen jetzt exakt die Daten vor, auf denen wir auch live im Rahmen der Tableau Kino Tour präsentieren.
Aber die dort gezeigten Daten gehen noch über das hier vorgestellte hinaus! Es fehlen noch zwei weitere Datensätze: Einerseits sind dies die Informationen zu Filmreihen (bspw. “Star Wars”, “Star Trek” oder “Herr der Ringe”), andererseits die Daten zum “Tatort”. Über die Beschaffung dieser beiden Datensätze werde ich noch zwei weitere Artikel verfassen – dieser hier ist sowieso schon viel zu lang.
Wer bis hierher durchgehalten und mitgemacht hat: Vielen Dank für’s Lesen, viel Spaß mit den Daten, und vielleicht sieht man sich ja bei einer der noch ausstehenden Stationen der Tableau Kino Tour!
[…] Hinter den Kulissen der Tableau Kino Tour – Teil 1: Die IMDb […]
[…] Hinter den Kulissen der Tableau Kino Tour – Teil 1: Die IMDb […]