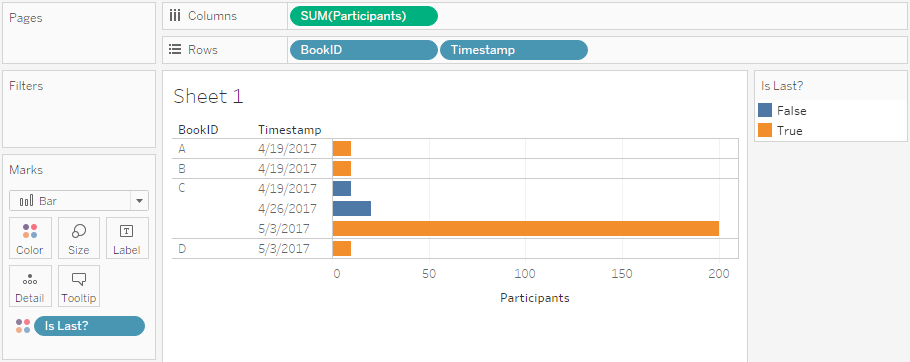
Imagine you have some kind of system that produces reports on your data – for this example I randomly decided to use bookings for events -, and these reports are published on a regular schedule. Now you want to see two things in your report:
- The current status of participants per event – both for past events (i.e. the actual number of participants) and for future events (i.e. the current number of people registered).
- An overview of how the number of people registered changed over time.
Also, your source system is publishing these data as .csv files. How can this be done?
Well, very easily using the new wildcard union feature introduced in Tableau Desktop 10.1! Read on to see how this can be done.